BIOはBaochip-1xに搭載されているI/Oコプロセッサだ。Baochip-1xは僕が設計をした、ほとんどがオープンソースの22nm SoCである。Baochip-1xの背景についてはこちらの記事で詳しく説明しているし、評価ボードはCrowd Supplyで入手できる。
この投稿では、BIOの成り立ちについて話そう。まず参考としてRaspberry Pi PIOを詳細に研究したところから始め、その後BIOのアーキテクチャに深く掘り下げていく。さらに、BIOのプログラミング例を3つ紹介する。うち2つはアセンブリ、1つはC言語だ。BIOの使い方だけに興味があるなら、背景の詳細は飛ばして、記事の後半にある「Design of the BIO」というセクションまでスキップしてもいいし、コード例に直接進んでも構わない。背景I/Oコプロセッサは、I/OタスクをメインCPUコアからオフロードする。メインCPUは何らかのマルチタスク方式を使って複数の優先度を処理しなければならず、それが応答時間の予測不能さにつながる。この予測不能な応答は、クリティカルな応答における望ましくないジッタや遅延として現れる。I/Oタスクにコプロセッサを専任させることで、汎用CPUの柔軟性を維持しながら、専用ハードウェアのステートマシンに迫る決定性を実現できる。
I/Oコプロセッサのよく知られた例が、Raspberry PiのPIOだ。PIOは4つの「プロセッサ」から構成され、それぞれが9命令を持ち、32ワードの命令メモリを備えている。GPIOのサイクル単位での正確な操作を容易にしながら、高い柔軟性を発揮するよう高度に調整されている。例えば、クロック、イン、アウトを備えたSPIの実装は、コンフィギュレーション修飾子と、わずか2つの命令で実現できる。これらはPIOのコンフィギュレーションで利用可能な副作用(コードの自動ラップアラウンドやFIFO管理など)によって「実質的なループ」として実行される: “.side_set 1”, “out pins, 1 side 0 [1]”, “in pins, 1 side 1 [1]",僕はBaochipに何らかの形のI/Oコプロセッサを欲しがっていたので、PIOを自分が知る最善の方法 — — つまりコピーすること — — で研究することにした。Lawrie Griffithのfpga_pioをフォークして出発点とし、欠けていたコーナーケースをすべて洗い出すために、大量の回帰テストと詳細なシミュレーションを行った。その結果、RP2040世代のPIOコアにかなり近い、仕様に完全に準拠したものができたと思う。このgithubリポジトリで公開している。PIOから学んだ教訓PIOクローンを構築してFPGAにコンパイルしてみて、僕は驚いた。PIOが驚くほど多くのリソースを消費するのだ。FPGAで使うことを考えているなら、PIOはスキップして、やりたいペリフェラルをRTLで直接実装したほうがいいだろう。
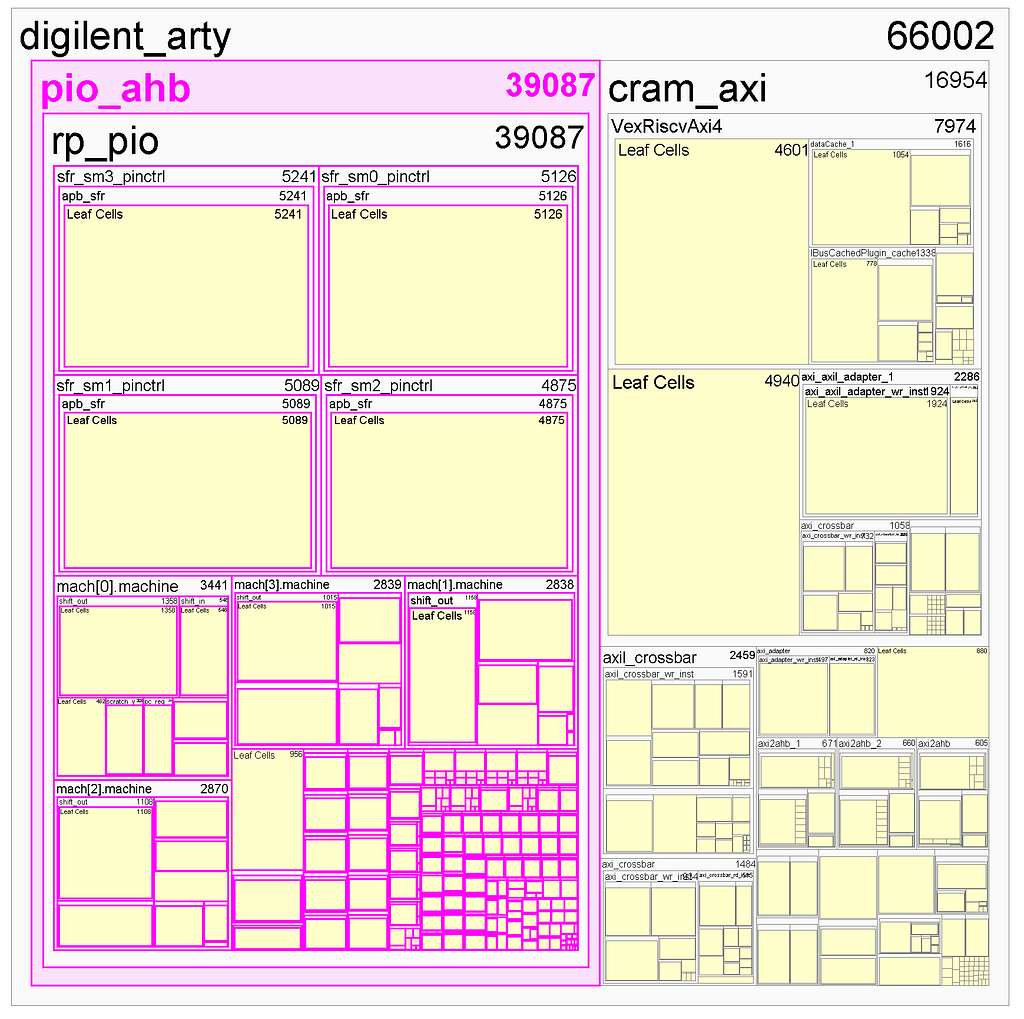
上記はXC7A100 FPGAをターゲットに配置配線したPIOコアの階層的リソースマップだ。PIOが占める部分をマゼンタでハイライトしている。FPGAの半分以上を消費しており、RISC-V CPUコア(右側の「VexRiscAxi4」ブロック)よりも多い!わずか9命令しか実行できないにもかかわらず、各PIOコアは約5,000のロジックセルで構成されている。比較すると、VexRiscv CPUは、IキャッシュとDキャッシュを除けばわずか4,600ロジックセルしか消費しない。
さらに、PIOコアのクリティカルパスはVexRiscvの少なくとも2倍悪い。FPGA設計ではVexRiscvだけであれば100MHzのタイミングクローズは容易だが、PIOコアが入ると50MHzでのタイミングクローズすら困難になる。
Vivadoのタイミング解析結果をざっと見てみると、何が起きているかの手がかりが得られる。

上記は設計中の最も長い組み合わせパスのひとつとして特定されたロジックパスであり、下記はそのセルの詳細レポートである。

問題は、コンピュータアーキテクチャそのものと同じくらい古い論争、すなわちCISC対RISCの議論に行き着く。PIOは「たった」9命令しか持たないが、各命令は信じられないほど複雑だ。単一の命令で、以下のすべてを1サイクル内に実行できるように調整されている:何らかの通常操作(JMP、WAIT、IN、OUT、PUSH、PULL MOV、IRQ、SET)プログラムカウンタのインクリメント……さらに、特定の条件に達したらプリセットされた場所にラップバックする32ビットバレルシフタを通じてデータを回転させ、潜在的な宛先/ソースとの間でやり取りするしきい値をチェックし、入力/出力FIFOを補充するかどうかを決定する(結合されている場合とされていない場合がある)別のピンをサイドセットする可能性割り込みフラグを計算し、結果に基づいてプログラムカウンタを変更する可能性複数のマシンが共有リソースにアクセスしようとした場合の優先度の競合を解決するロジック面積の多くは、ピンマッピングオプションの柔軟性を処理するために必要なシフタによって消費されていることがわかる。PINCTRLレジスタを見ると、4つの「ベース」セレクタがあり、これは4つの32ビットバレルシフタと、シフタの末端に取り付けられた構成可能なラン長を意味する。基本的に、PIOの「回転+マスク」部分は、ステートマシン自体よりも多くのロジック面積を消費しており、これら一連の回転マスクとクロック分周、FIFOしきい値計算を1サイクルに押し込むことは、時間的にも非常にコストが高い。PIOのオプションの柔軟性は、基本的にFPGAの上でFPGAのような配線ネットワークをエミュレートしていることを意味し、それが非効率性の原因だ。
おそらく僕のPIOの実装には、もっと効率的にするための最適化が欠けているのかもしれない。しかし、僕はサイクル精度を維持することにかなり注意を払っており、その過程で、たとえタイミングクローズを改善できたとしても、忠実性に影響を与える最適化は避けなければならなかった。
FPGA研究から得た教訓は、ASICフローにも引き継がれた。Baochip-1xの生成に使用したのと同じツールチェーンにコードベースを通したところ、ゲート数と遅延も同様に大きく、そして「遅い」ことがわかった。「遅い」と引用符を付けたのは、GPIOのビットバンギングという本来の用途には十分な速度だからだ。ASICで可能なことに比べれば遅い、というだけの話だ。PIOユーザへの注意事項どうやらPIOには少なくとも1つの特許が関わっているようだ。方針として、僕は特許を読まないことにしている。したがって、この再実装が特許を侵害しているかどうかについて意見を述べることはできない。しかし、これはRaspberry Pi財団が自社ブロックのオープンソースによる再実装を歓迎していないというシグナルだ。彼らは僕に対してこのブロックのソースコードを削除するよう強制していないが、この共有したリファレンスコードを使用しようとする人は誰でもこの問題を認識し、製品に組み込むリスクを考慮すべきだ。別のアプローチ僕の専門的な訓練とキャリアの影響は、コンピュータアーキテクチャにおけるRISC陣営にしっかりと位置づけられている。博士課程の指導教官だったTom Knightは、ハードウェアアーキテクチャについて考えるとき「重要なのは配線だ、バカ」とよく言っていた。複雑さは将来の負債になること(別の言い方をすれば「シンプルな設計は新しいプロセスへの移植が容易だ」)、ハードウェアの目新しさは優れたソフトウェアツールなしでは無価値であること、を彼は教えてくれた。
その結果、PIOは抽象的な思考概念としてはなかなか面白いが、実装者としては本当に気になる存在だった。バレルシフタはハードウェア的に高コストだ。バレルシフタにはたくさんの配線があり、僕は配線を慎重に使うように訓練されてきた。さらに、カスタム命令セットはコーディングが難しく、特に命令実行に影響を与える帯域外の設定があるとなおさらだ。数ヶ月を費やして大量のPIOコードを書いた後でも、僕はまだ最初のトライで動かすことに苦労し、カスタムPIOコードをデバッグするためにVerilatorシミュレーションに大きく依存していた(他のPIOプログラマーがどのようにデバッグしているのか、僕には見当もつかない。しかし、もし何かあるとすれば、PIOの再実装の最大の利点のひとつは、Verilatorを使ったシミュレーションで実際にPIOコードをデバッグできることかもしれない)。
結論として、この作業をすべて終えた後、僕は力を得たというよりも疲弊していると感じた。PIOは、僕が期待していたほど楽しくなかったのだ。
そこで、ふと思いついた。PIOのオールRISCバージョンがあったらどうだろう?こうして「BIO」が生まれた。ひねりのあるRISC実のところ、RISC-V 32ビットコアは非常にコンパクトにできる。Claire Xenia WolfのPicoRV32はその好例だ。このコアは、Xilinx 7シリーズFPGA上で761スライスLUTまで縮小し、200MHz以上の速度を達成できる。それにもかかわらず、完全なRV32I命令セットを実行できる。つまり、RISC-Vエコシステムで利用可能な優れたソフトウェアツール群を活用できるのだ。
もちろん、欠点もある。ひとつは、I/Oを決められたタイミングで切り替えたい場合、サイクルカウント地獄に陥ることだ。もうひとつは、単にコアをロード/ストア命令でI/Oレジスタに配線すると、4つのコアがGPIOレジスタのバンクを競合することになり、多くの非決定性やウェイトステート、その他の複雑さが生じる。つまり、4つのPicoRV32コアをAXIバスに接続してGPIOをビットバンギングすればPIOのような結果が得られる、という単純な話にはならない。
幸い、僕には秘策がある。数十年前、博士論文のために「ADAM」と呼ばれるCPUアーキテクチャを設計した。詳細のほとんどはここでは関係ないが、ひとつのトリックだけは重要だ。レジスタファイルに通常のレジスタだけを置くのではなく、その一部をキューにマッピングし、アーキテクチャレベルでfull/emptyのブロッキングセマンティクスを持たせるのだ。このトリックにより、軽量な命令レベルの並列性から、プロセッサとI/Oリソース間の高速で低レイテンシな通信まで、多くのことが可能になる。ここで使うのは後者の特性だ。BIOの設計BIOの設計は、RV32Eとして構成されたPicoRV32から始まる。このモードでは、完全な32レジスタ(ゼロレジスタを含む)の代わりに、16レジスタ(r0~r15のみ)がRV32E仕様の正式な部分となる。そして僕は、r16~r31を悪用して、一連の「レジスタキュー」とGPIOアクセス、同期プリミティブをマッピングする。下図は、4つのRV32Eコアそれぞれで公開される最終的なレジスタセットを示したものだ。

(上図で、ベージュ色の長方形は通常の読み書きセマンティクスを持つレジスタ、ラベンダー色の長方形は様々な条件に基づいてCPU実行をブロックできるレジスタである。)
テキストでの「上位バンク」レジスタの説明:FIFO - 8段FIFOの先頭/末尾アクセス。コアはオーバーフロー/アンダーフロー時に停止する.
- x16 r/w fifo[0]
- x17 r/w fifo[1]
- x18 r/w fifo[2]
- x19 r/w fifo[3]
Quantum - ホストが設定したクロック分周パルス、またはホストが指定したGPIOピンからの外部イベントが発生するまでコアは停止する .
- x20 -/w halt to quantum
GPIO - データピンのビットクリアには「クリア時に0」というセマンティクスに注意!これは、ビットバンギングでデータピンを扱う際に反転なしでシフト&ムーブができるようにするためだ。方向はより「従来型」の意味を保持しており、クリアまたはセットのどちらでも「1」の書き込みがアクションを引き起こす。ピン方向のトグルはタイトな内部ループではあまり使われないからだ
- x21 r/w write: (x26 & x21) -> gpio pins; read: gpio pins -> x21
- x22 -/w (x26 & x22) -> a
1in x22 will set corresponding pin on gpio - x23 -/w (x26 & ~x23) -> a
0in x23 will clear corresponding pin on gpio - x24 -/w (x26 & x24) -> a
1in x24 will make corresponding gpio pin an output - x25 -/w (x26 & x25) -> a
1in x25 will make corresponding gpio pin an input - x26 r/w mask GPIO action outputs
Events - 共有イベントレジスタ上で動作する。ビット[31:24]はFIFOレベルフラグにハードワイヤされており、ホストによって構成される。ビット[31:24]への書き込みは無視される.
- x27 -/w mask event sensitivity bits
- x28 -/w
1will set the corresponding event bit. Only [23:0] are wired up. - x29 -/w
1will clear the corresponding event bit Only [23:0] are wired up. - x30 r/- halt until ((x27 & events) != 0), and return unmasked
eventsvalue
Core ID & debug:
- x31 r/- [31:30] -> core ID; [29:0] -> cpu clocks since reset拡張レジスタセットの最も興味深い側面は、ブロッキングレジスタだ。これらのレジスタでは、特定のFIFO関連の条件が満たされるまで、実行中の現在の命令が完了しないことがある。例えば、x16-x19のいずれかを読み取ると、共有FIFOのひとつから値をデキューしようとする。対象のFIFOが空の場合、FIFOに値が現れるまでCPUの実行は停止する。同様に、x16-x19への書き込みは、FIFOに空きがある場合にのみ完了する。FIFOがいっぱいになると、少なくとも1つのエントリが別のコンシューマによって消費されるまで実行は停止する。
I/Oプロセッサの重要な目的のひとつは、ハードリアルタイム保証を満たすことだ。簡単な例としては、定期的な間隔でのイベントのタイムリーなシーケンスの保証がある。これを支援するために、レジスタx20とx30は、非同期条件が満たされるまでCPUの実行を停止できるように配線されている。

x20へのアクセスを利用して、クォンタム間隔でCPU操作を自動的にスケジュールする方法の図解x20の場合、CPUは「クォンタム」時間が経過するまで停止する(内部の分数クロック分周器、またはGPIOピンからの外部クロックソースによって定義される)。x30の場合、CPUは「イベント」条件(FIFOが一定の満杯状態に達するなど)が満たされるまで停止する。
「クォンタムまで停止」レジスタは、クォンタムレジスタへの書き込み間の最長コードパスよりもクォンタムが長いことが保証されている場合、コード内でのサイクルカウントの必要性を排除できる。これは、単一メガヘルツ以下の速度で動作するプロトコルではしばしば当てはまる。
BIOは「BDMA」拡張を介してDMAを行うこともできる。この拡張により、PicoRV32コアのロード/ストアユニットがSoCのバスにアクセスできるようになる。アクセス競合時には「単純な」優先度解決機能が働く(最も番号の小さいコアが常に勝利し、他のコアは停止する)。この機能を追加することで、BIOはメインメモリとの間でデータをシャトリングするスマートDMAエンジンとしても機能できるようになるが、ベースとなるBIOコアのサイズは約50%増加する。最速のDMAエンジンほど高速ではないが、スキャッタギャザー、回転、シャッフル/インターリーブなど、かなり複雑なデータアクセス変換を実装でき、例外や特殊なケースを処理するためのある程度のスマートさも備えている。
補足として、メインメモリへのアクセスはホワイトリストによって制限されており、デフォルトでは空である。したがって、BDMA機能を使用しようとする前に、まずBIOがアクセスを許可されているメモリ領域を宣言しなければならない。これは、ホストCPUのセキュリティ機能をバイパスする方法としてBDMAが悪用されるのを防ぐのにも役立つ。簡単なBIOコード例BIOのFIFOレジスタの使い方の概要を説明するために、DMA操作の例を見てみよう。ここでは、ホワイトリストがすでにVexriscvコアによって設定されているものと仮定する。この例では、DMA操作を2つの部分に分解する。ひとつのBIOコアがメモリのフェッチとストアを担当し、別のBIOコアがアドレスの生成を担当する。
フェッチ/ストアBIOコアのコードは非常にシンプルだ。アドレスオフセットがx16またはx17(それぞれFIFO0とFIFO1)から来る一連のロード(lw)とストア(sw)にすぎない:bio_code!(dma_mc_copy_code, DMA_MC_COPY_START, DMA_MC_COPY_END, “20:”, “lw a0, 0(x16)”, // unrolled for more performance “sw a0, 0(x17)”, “lw a0, 0(x16)”, “sw a0, 0(x17)”, “lw a0, 0(x16)”, “sw a0, 0(x17)”, “lw a0, 0(x16)”, “sw a0, 0(x17)”, “j 20b” );このコードスニペットはRustマクロでラップされている。BIOはほぼ標準のRV32Eを使用しているため、既存のRISC-Vツールを活用できる。この場合、bio_code!マクロはRustアセンブリコードに「DMA_MC_COPY_START」と「DMA_MC_COPY_END」という識別子を注釈として付ける。これらの識別子により、別個のコードローダがアセンブルされたバイナリブロックの開始と範囲を特定し、実行時にBIOメモリにコピーできるようになる。
上記の例では、x16が空でアドレスが生成されるのを待っているため、CPUは最初の命令で停止する。
一方、2番目のCPUコアは以下のコードを実行する:bio_code!(dma_mc_src_addr_code, DMA_MC_SRC_ADDR_START, DMA_MC_SRC_ADDR_END, “20:”, “mv a0, x18”, // src address on FIFO x18 “li x29, 0x500”, // clear done state “li x28, 0x400”, // partial done “mv a1, x18”, // # bytes to copy on FIFO x18 “add a2, a1, a0”, “21:”, “mv x16, a0”, “addi a0, a0, 4”, “bne a0, a2, 21b”, “j 20b” );このコードは、ホストによってDMAのパラメータが発行されるまでCPUを待機させる。この場合、ソースアドレスがFIFO2(順番にx18に現れる)にエンキューされ、その後にコピーするバイト数が続く。これらのデータが利用可能になると、コアは可能な限り多くのアドレスを生成し、x16をソースアドレスで満たしていく。x16がいっぱいになってジェネレータがブロックされるか、コピーすべきバイト数に達するまで続く。
3番目のCPUは、FIFO3から宛先アドレスを読み取り、x17に書き込みアドレスを生成する、非常によく似たコードブロックを実行するために使用される。
このシンプルな例は、3つのシンプルなCPUコアを並列に実行させることで、単一のコアで達成できるよりも高いDMA帯域幅を実現できることを示している。FIFOとGPIOの詳細各FIFOは、ホストと4つのコアの合わせて5つのソースのいずれかからデータを受け取ることができる。FIFOのエンキュー側には、以下のルールを持つ優先度解決機能がある:ホストが常に優先される番号の小さいコアは番号の大きいコアより優先される競合する書き込みは、そのコアの順番が回ってくるまで停止するFIFOへのアクセスの「公平性」を保証する他の仕組みはない。
FIFOのデキュー側は、複数のデキュー要求が同じサイクルに到着した場合、単にFIFOの出力を複数のリスナに複製する。明示的なコア間同期を保証する仕組みはないが、FIFOから読み取る前に「イベントまで停止」または「クォンタムまで停止」のレジスタアクセスを使用することで、プログラマは複数のコアが同じサイクルに単一のFIFOソースから読み取ることを保証できる。
GPIOピンにもビット設定用の同様の優先度解決機能があるが、違いとして、書き込みで優先度に「負けた」コアのリクエストは単に破棄される。優先度の高いコアが優先度の低いコアのGPIOリクエストを即座に上書きすると見なされるからだ。
GPIOアクセスのセマンティクスは、生データを任意のピンに高速にシフトするために最適化されている。特に、ビットのクリアはビットに「0」を書き込むことで行われる。これは、アクションがビットに「1」を書き込むことで示される他のすべてのケースとは顕著な例外だ。この例外が導入された理由は、パラレル・ツー・シリアルのビットバングプロトコルのコアループからビット反転を除去できるからであり、これはおそらくBIOブロックにとって最もパフォーマンスが重要なアプリケーションだからだ。クォンタムへのスナップ:SPIの例SPIの話が出たところで、SPIビットバング実装の例を見てみよう。この場合、2つのコアが並列に動作する。ひとつはシフトアウトとクロックを処理し、もうひとつはシフトインを処理する。ピンのマッピングはコードの別の場所で設定され、GPIO 7を受信、GPIO 8を送信、GPIO 9をクロック、GPIO 10をチップセレクトとする。
クォンタムへのスナップは、エッジが揃うようにするために使用される。この実装では、クォンタムはSPIクロックレートの2倍で動作する必要がある(したがって、25MHzのSPIクロックに対して50MHzとなる。これはBIOコアが700MHzで動作していれば達成可能だ。PicoRV32ではパイプライン化されていないため、典型的な命令は実行に約3サイクルかかることに注意)。
最初のスニペットは、TX+クロックを管理するコアで実行されるものだ。最初の数命令でビットマスクと一時変数を設定し、その後実際のビットをシフトするルーチンはアンロールされる。これにより、ビット間のブランチやループのペナルティを支払わなくて済む。ループアンロールはBIOコードで広く使われている。なぜなら、PicoRV32あたり4KiBの広々としたコード空間があるからだ。“82:”, // machine 2 - tx on bit 8, clock on bit 9, chip select on bit 10 “li x1, 0x700”, // setup output mask bits “mv x26, x1”, // mask “mv x24, x1”, // direction (1 = output) “li x2, 0x100”, // bitmask for output data “not x3, x2”, “li x4, 0x200”, // bitmask for clock “not x5, x4”, “li x6, 0x400”, // bitmask for chip select “not x7, x6”, “mv x21, x6”, // setup GPIO with CS high, clock low, data low “mv x20, x0”, // halt to quantum, make sure this takes effect
“20:”, // main loop “mv x15, x16”, // load data to transmit from fifo 0 - halts until data is available “mv x23, x7”, // drop CS “slli x15, x15, 8”, // shift so the LSB is at bit 8 “mv x20, x0”, // wait quantum for CS hold time
// bit 0 “and x22, x15, x2”, // set data bit, if it’s 1 “or x23, x15, x3”, // clear data bit, if it’s 0 “mv x20, x0”, // wait quantum for data setup
“mv x22, x4”, // clock rise “srli x15, x15, 1”, “mv x20, x0”, // wait quantum for data hold
// bit 1 “and x22, x15, x2”, // set data bit, if it’s 1 “or x23, x15, x3”, // clear data bit, if it’s 0 “mv x23, x5”, // clock fall “mv x20, x0”, // wait quantum for data setup “mv x22, x4”, // clock rise “srli x15, x15, 1”, “mv x20, x0”, // wait quantum for data holdこのコードは各ビットについて続いていくが、簡潔のためビット1以降は省略している。完全なコードはgithubリポジトリで見ることができる。
2番目のスニペットは、RXを管理するコアで並列に実行される。// wait until CS falls “31:”, “and x8, x6, x21”, “bnez x8, 31b”,
// bit 0 “srli x14, x14, 1”, // shift bit into place // wait until clock rises “mv x20, zero”, // halts until rising edge on bit 9 (configured by host) “and x9, x2, x21”, // mask the bit “slli x9, x9, 7”, // move to MSB “or x14, x9, x14”, // OR into the result
// bit 1 “srli x14, x14, 1”, // shift bit into place // wait until clock rises “mv x20, zero”, // halts until rising edge on bit 9 (configured by host) “and x9, x2, x21”, // mask the bit “slli x9, x9, 7”, // move to MSB “or x14, x9, x14”, // OR into the resultこのコードも同様に残りのビットについて続くが、簡潔のため省略している。
ここで注目すべきは、x20の「クォンタムへスナップ」のソースが単にTXによって生成されたクロック信号であるということだ。したがって、RXはSPIクロック信号に同期した方法で自動的にトリガーされる。どこにでもあるトレードオフ:面積、クロックレート、コード空間BIOの使い方のコード例だけを探しているなら、次の2つのセクションはスキップして、BIOでC言語を実行するセクションに直接進んでも構わない。しかし、このブロックの基礎となる設計とアーキテクチャに興味がある人にとっては、PIOとBIOの実装を並べて比較し、これらのアーキテクチャ上の決定が実際の実装にどのような影響を与えるかを見ることは有益だろう。
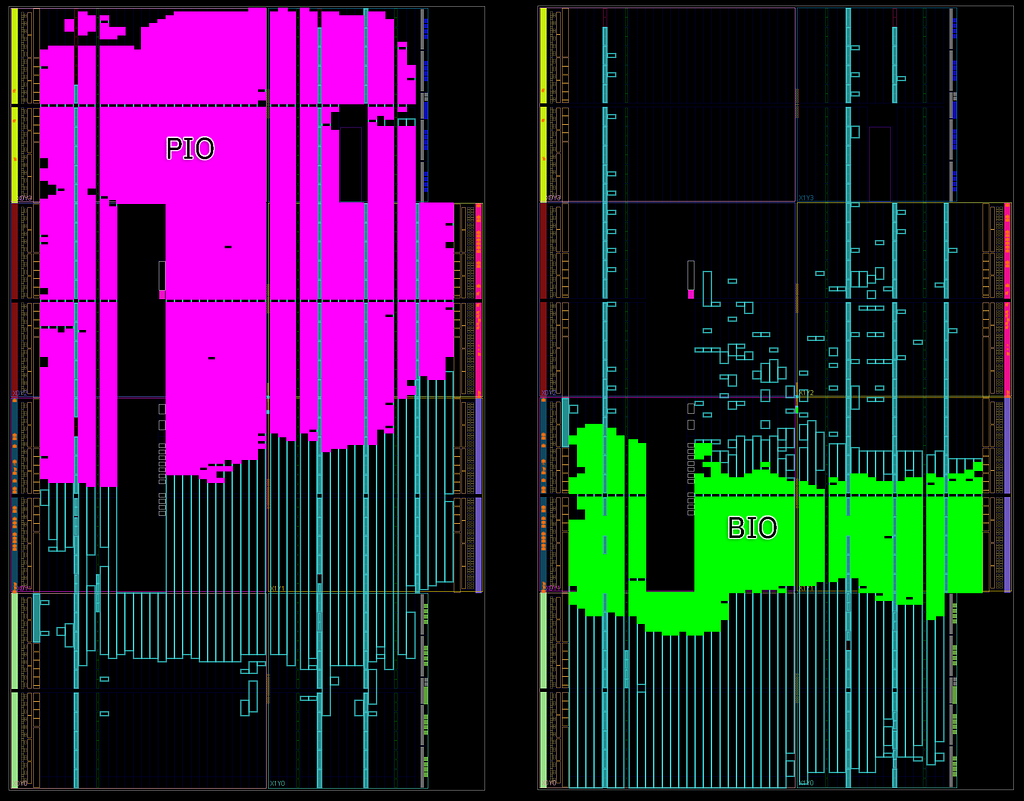
上図は、同じArtix 7シリーズFPGAにコンパイルされたPIOとBIOのフロアプランを並べて比較したものだ。重要な点は、PIOの9命令よりも豊かなRV32E命令セットを持ちながら、BIO(緑色で表示)はPIO(マゼンタで表示)の面積のごく一部しか消費していないことだ。

上図は階層的リソース使用量マップで、この投稿の前半に示したPIOのものと比較できる。BIOは14,597セルを使用しているのに対し、PIOは39,087セルを使用している。数字で見ると、BIOはPIOの約半分の面積だ。さらに、ASICフローに移植した場合、BIOが達成するクロックレートは、同じプロセスノードで実装されたPIOの4倍以上である。
クロックレートにあまり夢中になる前に、注意すべき点がある。PicoRV32コアを使うとコアあたりのクロックレートは高くなるが、各コアがクロックサイクルと命令あたりにできることは少ない。これは古典的なCISC対RISCのトレードオフがそのまま表れたものだ。PicoRV32はコンパクトさのために設計されており、パフォーマンスのためではない。そのため、命令あたり約3サイクルかかり、PIOが1命令でできることを実行するには数命令が必要になる。これは、SPIのような非常に単純な処理では、BIOはPIOと同じピーク速度には到達しないことを意味する。しかし、より豊富な命令セットと大きな命令メモリのおかげで、固定小数点信号処理や、様々なプロトコルにデータをフレーミングするためのビットスタッフィングなど、より多くの機能を実装できる。したがって、RAMからのDMAバーストでビットを可能な限り高速にシフトアウトするビットバンガーだけが必要なら、PIOの方が適している。しかし、よりフル機能のI/Oコプロセッサが必要なら、BIOの方が適している。
とはいえ、より多くのゲートを使っても構わないのであれば、PicoRV32コアをより高性能なパイプラインコアに交換して、サイクルあたりの命令数を1に近づけることもできる。BIOはオープンソースなので、面積とパフォーマンスのトレードオフを最適化するのは自由だ!良いニュースは、「クォンタムへスナップ」機構を正しく使えば、異なるBIO実装でも同じコードを実行しながら、同じサイクル精度の結果を達成できることだ。
PIOとBIOのもうひとつの違いは、PIOは32命令しか保持できない命令メモリで済ませているのに対し、僕は各BIOコアに広々とした4KiBのRAMを与えることを選んだことだ。ここでもまた、トレードオフが存在する。メモリのトレードオフについてPIOは4つのコアで単一の32エントリの命令メモリを共有している。4つのコアはそれぞれ、毎サイクルこの命令メモリに独立してアクセスできる。この32エントリのメモリは、おそらく大量のフリップフロップで実装されている。なぜなら、4ポートのRAMハードマクロはあまり一般的ではなく、PIOのアプリケーションにとって適切な性能調整がされている可能性も低いからだ。したがって、PIOは4つのコアすべてで同じ32命令を再利用するという意味では効率的だが、それらの命令のコピーを空間的に分散した4つのコアに中継するために何らかのペナルティを支払っている可能性がある。
一方、仮にRAMのハードマクロを活用できたとしても、マクロのオーバーヘッドが面積を支配するようになる特定の最小サイズが存在する。32ワード×32ビット幅のRAMマクロは、ASICプロセスでは極めて高いオーバーヘッドを持つだろう。おそらく面積の80%以上が行/列ドライバとセンスアンプになるため、結局フリップフロップで作るのとほぼ同じ面積になるだろう。
しかし、RAMのオーバーヘッドはスケーラビリティが高く、ビット容量の平方根にほぼ比例する。最適なポイントはプロセスノードによって異なる。Baochip-1xのいくつかの顕微鏡写真を見ると、シングルポートRAMマクロは、アレイサイズが約512×32ビットのジオメトリを超えるまで、オーバーヘッドが支配的であることが経験的にわかる。

上左:22nmプロセスの256×27 SRAMマクロの顕微鏡写真。上右:同じ画像で、ストレージアレイをティール色で、SRAMマクロ全体の境界を赤色でハイライトしたもの。マクロのオーバーヘッド領域には、ラインドライバ、アドレスデコーダ、センスアンプなどの回路が含まれる。これらのオーバーヘッドを考慮して、僕は各PicoRV32 CPUの専用メモリとして、4KiB(1024×32)のシングルポート高速RAMマクロを使用することにした。4KiBは、たまたまRV32 CPUの仮想メモリページのサイズとちょうど同じだ。ビットバンギングI/Oルーチンのほとんどは数百バイト未満しか消費しないので、BIOには高レベルの処理をオフロードするための十分なコード空間がある。BIOでのC言語プログラミングビットバンギングのアセンブリルーチンを手書きするのは楽しいが、固定小数点演算やプロトコルスタックなどの高レベル機能を実装するのは、アセンブリでは面倒でエラーが発生しやすい。より複雑なコードを容易にするために、僕はBIOプログラム用のCツールチェーンを開発した。これらのプログラムはRustアセンブリマクロにコンパイルされるため、最終的なXous OSのコンパイルとリンクは、バイナリブロブなしで純粋なRustを使って行われる。
Xous内部でC言語の手法を開発するのは厄介だ。なぜなら、Xousエコシステムが純粋なRustであることの重要な利点のひとつは、ツールを維持する必要がないことだからだ。Xousイメージのビルドに必要な唯一のツールは安定版のRustであり続けたい。ビルドプロセスにCコンパイラが導入された瞬間、配布ごとに異なるCツールチェーンの寄せ集めをかき分けなければならなくなり、開発者の摩擦とメンテナンスの負担が大幅に増加する。
この問題に対する僕たちの解決策は、少なくとも現時点では、Zigエコシステムのclang Cコンパイラを借用することだ。ZigはそのツールチェーンをPythonパッケージとして配布している。これは、事実上すべてのコンピュータに何らかの形のPythonディストリビューションが存在するという前提に基づいている。したがって、BIO用のCコードをビルドするには、Pythonを使ってZigツールチェーンをインストールし、Zigツールチェーンに組み込まれたCコンパイラを使ってCコードをビルドする:ユーザーは python3 -m pip install ziglang を使ってZigをインストールする。BIOスクリプトと互換性があるのは0.15ツールチェーンのみだ。次に、libs/bio-lib/src/c ディレクトリ内で python3 -m ziglang build -Dmodule= を使って、BIO CプログラムをRustアセンブリマクロにコンパイルする。ビルドスクリプトはCコードをclang中間アセンブリにコンパイルし、それをPythonスクリプトに渡す。PythonスクリプトはそれをRustマクロに変換し、Xousにビルド可能なアーティファクトとしてチェックインする。これにより、純粋なRustツールチェーンが使える。Pythonスクリプトはまた、BIOコアのエラッタを引き起こす可能性のある特定のモチーフについてアセンブリコードをチェックし、自動的にパッチを適用する。したがって、Cツールチェーンが必要になるのは、開発者がCコードを変更する必要がある場合だけだ。既存のCプログラムを再利用するにはRustだけが必要になる。副次的な効果として、これはZig開発者がBIOコードを書くための入口にもなる。
以下は、BIO用C言語がどのようなものかを示す例だ:// pin is provided as the GPIO number to drive // strip is an array of u32’s that contain GRB data // len is the length of the strip void ws2812c(uint32_t pin, uint32_t *strip, uint32_t len) { uint32_t led; // sanity check the pin value if (pin > 31) { return; } uint32_t mask = 1 « pin; uint32_t antimask = ~mask; set_gpio_mask(mask); set_output_pins(mask); // ensure timing with a nil quantum here clear_gpio_pins_n(antimask); wait_quantum(); // main loop for (uint32_t i = 0; i < len; i++) { led = strip[i]; for (uint32_t bit = 0; bit < 24; bit++) { if ((led & 0x800000) == 0) { // 2 hi set_gpio_pins(mask); wait_quantum(); wait_quantum(); // 5 lo clear_gpio_pins_n(antimask); wait_quantum(); wait_quantum(); wait_quantum(); wait_quantum(); wait_quantum(); } else { // 5 hi set_gpio_pins(mask); wait_quantum(); wait_quantum(); wait_quantum(); wait_quantum(); wait_quantum(); // 5 lo clear_gpio_pins_n(antimask); wait_quantum(); wait_quantum(); wait_quantum(); wait_quantum(); wait_quantum(); } led «= 1; } } } void main(void) { uint32_t pin; uint32_t actual_leds; uint32_t rate; // blocks until these are configured pin = pop_fifo1(); actual_leds = pop_fifo1(); rate = pop_fifo1();
while (1) {
ws2812c(pin, led_buf, actual_leds);
rainbow_update(actual_leds, rate);
for (uint32_t i = 0; i < 100000; i++) {
wait_quantum();
}
}
}これはWS2812C LEDプロトコルをビットバンギングする例だ。ソースコードはmainとヘッダに分割されている。ここでは「クォンタム」機能を活用して、サイクルカウントに頼らずに正確なパルスタイミングを実現している。「クォンタム」は150nsの周期に設定されており、必要なすべてのhigh/lowタイミングパターンを均等に分割できる。ループ内のすべての計算が次のクォンタムまでに終了する限り、WS2812Cのタイミング要件は満たされる。
初期段階のCライブラリには固定小数点演算ライブラリも含まれており、デモではLEDストリングの駆動に加えてカラーエフェクトの計算もできる。デモプログラム全体は、固定小数点演算ライブラリを含めても、BIOメモリの約25%、4096バイト中1062バイトしか使用していない。「colorwheel」デモのコードや、Cツールチェーンの使い方についてはbio-libのREADMEを参照してほしい。振り返りPIOとBIOは、I/Oコプロセッサ実装における異なるアーキテクチャ哲学のケーススタディだ。まとめると:
PIO:CISCアーキテクチャ各命令に豊富な設定オプションサイクルカウントが容易で、手作りされたビットバング波形と決定論的な応答時間が可能4つのコアすべてで共有される小さな命令メモリ各コアが異なる機能を実装することに最適化より大きなロジック面積より低いクロックレートだが、IPCは1で保証カスタムツール、コンパイラなし(僕の知る限り)クローズドソース、少なくとも1つの特許に抵触する可能性ありBIO:RISCアーキテクチャ各命令での操作はプリミティブ:単一のPIO命令に匹敵するには複数の命令が必要サイクルカウントはより難しいが、スタッラブルレジスタにより決定論的なリアルタイム性能を実現FIFOによる直接的なコア間通信のためのISA拡張各コアにプライベートな大きな命令メモリ複数のコアが協調してパフォーマンスを向上させることに最適化。または、各コアが異なる機能をより低い速度で実装することに最適化より小さなロジック面積より高いクロックレートだが、IPCは0.2~0.33の範囲(より多くのロジック面積を使うことで改善可能)RV32E用の標準ツール(コンパイラ、アセンブラ、マクロ、デバッガなど)を活用オープンソース、特許なし現在のBIO実装は、面積をパフォーマンスよりも優先しており、適度なサイズのFPGAにペリフェラルとして常識的に統合できるようにしている。この実装上の選択により、BIOはPIOのようにDVIをビットバンギングすることはできないが、Arty A7–100Tボード上で余裕を持って収まる。しかし、僕がBIOが本当に輝くと思うのは、プロトコルスタック管理のようなタスクをCPUからオフロードすることだ。これらのトレードオフにもかかわらず、700MHzで動作するBaochip-1xの実装は、25MHzのSPIバスを快適にエミュレートでき、これは様々な組み込みアプリケーションにとって十分な速度だ。
リソース
始めるのに役立つ以下のリソースがGitHubで利用可能だ。BIO開発者向け:Xousネイティブのサンプルライブラリ。これらのライブラリのひとつをテンプレートとしてコピーし、拡張することから始めよう!ハードウェアエンジニア向け:BIOのRTL。SystemVerilogで書かれており、AHB(有効にした場合はDMA用にAXI)を使用してホストシステムに統合される。検証エンジニア向け:BIOハードウェアのユニットテスト最後に、実際のチップ上のBIOハードウェアを手に入れることに興味があるなら、Crowd Supplyの「Dabao」開発ボードキャンペーンをチェックしてほしい。
みんなが僕がこれを創作するのと同じくらい、ハックを楽しんでくれることを願っている!
この記事は、Bunnie Huangのブログ記事BIO: The Bao I/O Coprocessorを、本人の許可を得て翻訳したもの。 Dabao Boardは、高須の勤務するスイッチサイエンスにて日本販売予定。 また、Dabao Chipの詳細についてDiscord(日本語チャネル含む)にてご意見募集中。
